Slurm作业管理系统
使用Slurm作业管理系统,当前debug作业队列设置为节点可以共享,但作业独占CPU core/GPU资源。多个用户可以提交作业到同一个节点上,但是节点上CPU core/GPU资源只能被单一作业占有使用。
作业管理系统常用命令如下: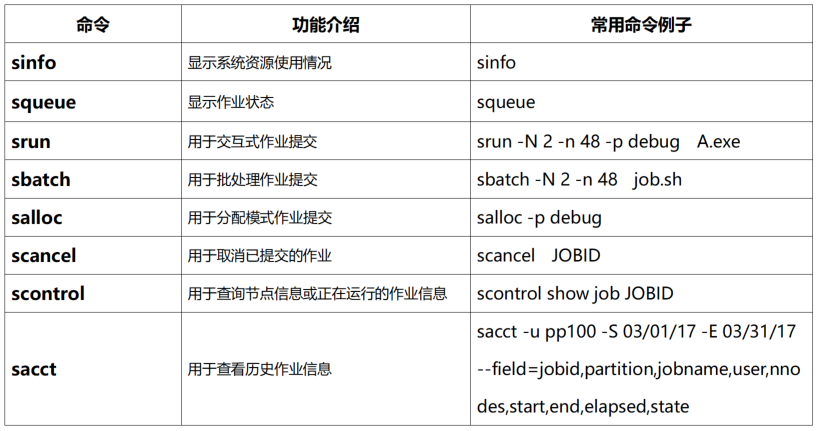
1、sinfo查看系统资源
sinfo得到的结果是当前账号可使用的队列资源信息,如下图所示:

其中,
第一列PARTITION是队列名,默认能使用的队列名为debug。
第二列AVAIL是队列可用情况,如果显示up则是可用状态;如果是inact则是不可用状态。
第三列TIMELIMIT是作业运行时间限制,默认是infinite没有限制。
第四列NODES是节点数。
第五列STATE是节点状态,idle是空闲节点,alloc是已被占用节点,comp是正在释放资源的节点,其他状态的节点都不可用,mix是该节点有作业在运行或有程序占用cpu导致的。
第六列NODELIST是节点列表。
sinfo的常用命令选项:
命令示例 | 功能 |
sinfo -n gpu001 | 指定显示节点gpu001的使用情况 |
sinfo -p debug | 指定显示队列debug情况 |
其他选项可以通过sinfo --help查询。
2、squeue查看作业状态
squeue得到的结果是当前账号正在运行作业的状态,如果squeue没有作业信息,说明作业已退出。

其中,
第一列JOBID是作业号,作业号是唯一的。
第二列PARTITION是作业运行使用的队列名。
第三列NAME是作业名。
第四列USER是超算账号名。
第五列ST是作业状态,R表示正常运行,PD表示在排队,CG表示正在退出,S是管理员暂时挂起,只有R状态会计费。
第六列TIME是作业运行时间。
第七列NODES是作业使用的节点数。
第八列NODELIST(REASON)对于运行作业(R状态)显示作业使用的节点列表;对于排队作业(PD状态),显示排队的原因。
squeue的 常用命令选项:
命令示例 | 功能 |
squeue -j 396 | 查看作业号为396的作业信息 |
squeue -u gliu | 查看集群账号为gliu的作业信息 |
squeue -p debug | 查看提交到debug队列的作业信息 |
squeue -w gpu001 | 查看使用到gpu001节点的作业信息 |
其他选项可通过squeue --help命令查看。
3、srun交互式提交作业
srun [options] program命令属于交互式提交作业,有屏幕输出,但容易受网络波动影响,断网或关闭窗口会导致作业中断。
srun 命令示例:
srun -p debug -w gk[11-15] -N 2 -n 12 -t 20 --gres=gpu:2 my_job.sh |
交互式提交my_job.sh程序。如果不关心节点和时间限制,可简写为:srun -p debug my_job.sh
其中,
-p debug 指定提交作业到debug队列;
-w gk[11-15] 指定使用节点gk[11-15];
-N 2 指定使用2个节点;
-n 12 指定运行的任务数为12, 默认情况下一个CPU核一个任务
-t 20 指定作业运行时间限制为20分钟。
--gres 申请其他通用资源,例如GPU卡等。 参数的值为:“gpu:2”表明需要申请2块GPU显卡资源。
注意:
提交作业时不显式指定显卡资源,默认情况下不能使用显卡进行计算。即忽略 –gres 参数,作业只能使用CPU计算资源。
Srun 的一些常用命令选项:
参数选项 | 功能 |
-N 3 | 指定节点数为3 |
-n 12 | 指定任务数为12, 默认一个CPU核一个任务 |
-p debug | 指定提交作业到 debug队列 |
-w gk[11-15] | 指定提交作业到gk11/gk12/gk13/gk14/gk15节点 |
-x gm[11-12] | 排除gm11、gm12节点 |
-o out.log | 指定标准输出到out.log文件 |
-e err.log | 指定重定向错误输出到err.log文件 |
-J JOBNAME | 指定作业名为JOBNAME |
-t 20 | 限制运行20分钟 |
--gres=gpu:2 | 为作业分配2块GPU显卡资源 (最大值为8) |
srun的其他选项可通过srun --help查看。
4、sbatch 后台提交作业
sbatch一般情况下与srun一起提交作业到后台运行,需要将srun写到脚本中,再用sbatch 提交脚本。这种方式不受本地网络波动影响,提交作业后可以关闭本地电脑。sbatch命令没有屏幕输出,默认输出日志为提交目录下的slurm-xxx.out文件,可以使用tail -f slurm-xxx.out实时查看日志,其中xxx为作业号。
* 可通过module来加载运行环境 如
module load gcc cuda
示例1、 单节点(20 核)
#!/bin/bash
#SBATCH --job-name=test # 作业名
#SBATCH --partition=gpu # cpu 队列
#SBATCH -n 20 # 总核数 20
#SBATCH --ntasks-per-node=20 # 每节点核数
#SBATCH --output=%j.out
#SBATCH --error=%j.err
示例2: 单节点GPU
#!/bin/bash #SBATCH --job-name=dgx2_test #SBATCH --partition=dgx2 #SBATCH --gres=gpu:4 #SBATCH -n 4 #SBATCH --ntasks-per-node 4 #SBATCH --mail-type=end #SBATCH --mail-user=YOU@EMAIL.COM #SBATCH --output=%j.out #SBATCH --error=%j.err
module load gcc cuda
./cudaTensorCoreGemm
|
示例3:MPI多节点并行
#!/bin/bash
#SBATCH -o job.%j.out
#SBATCH --partition=C032M0128G
#SBATCH --qos=low
#SBATCH -J myFirstMPIJob
#SBATCH --nodes=2
#SBATCH --ntasks-per-node=32
#SBATCH --time=120:00:00
module load intel/2017.1
module load vasp/5.4.4-intel-2017.1
srun hostname -s | sort -n >slurm.hosts
mpirun -n 64 -machinefile slurm.hosts vasp_std > log
示例4(一次提交多任务)
编写脚本job3.sh,内容如下:
#!/bin/bash srun -n 8 A.exe & srun -n 8 B.exe & srun -n 8 C.exe & wait |
然后在命令行执行sbatch -N 1 -p debug job3.sh,这里是单节点同时提交3个任务,每个任务使用8个进程。这里“wait” 需要3个任务全部执行完毕,作业才会退出。
sbatch 的一些常用命令选项基本与srun的相同,具体可以通过sbatch --help查看。
注意:
与srun 一样,若作业需要使用GPU显卡资源, 需要在sbatch脚本中或在sbatch的命令行的参数中使用--gres=gpu:n (n为显卡数量)
5、salloc 分配模式作业提交
salloc命令用于申请节点资源,一般用法如下:
1、执行salloc -p debug; 2、执行squeue 查看分配到的节点资源,比如分配到gj16; 3、执行ssh gj16登陆到所分配的节点; 4、登陆节点后可以执行需要的提交命令或程序; 5、作业结束后,执行scancel JOBID释放分配模式作业的节点资源。 |
6、scancel 取消已提交的作业
scancel 可以取消正在运行或排队的作业。
scancel的一些常用命令示例:
命令示例 | 功能 |
scancel 343 | 取消作业号为343的作业 |
scancel -n test | 取消作业名为test的作业 |
scancel -p debug | 取消提交到debug队列的作业 |
scancel -t PENDING | 取消正在排队的作业 |
scancel -w gpu001 | 取消运行在gpu001节点上的作业 |
scancel的其他参数选项,可通过scancel --help查看。
7、scontrol 查看正在运行的作业信息
scontrol命令可以查看正在运行的作业详情,比如提交目录、提交脚本、使用核数情况等,对已退出的作业无效。
scontrol的常用示例:
scontrol show job 345 |
查看作业号为345的作业详情。
scontrol的其他参数选项,可通过scontrol --help查看。